CHALLENGING RESEARCH AREAS IN DATA SCIENCE
Author: Aytöre Arıkan
The century we live in is an era in which companies, organizations, and social networks
are built with an excellent ground based on data treasure. Modern technology allows us to store
the knowledge that we have produced. Even the historian Yuval Noah Harari explains this
condition with “Dataism” (Rapose, 2021). However, the information that we store has been
blasted. In addition to the effect of the explosion, which is touching everyone, what about the
quality? Do they offer us insight? Do they help us enhance or remain where they are and wait
to be seen? Do not worry; the answers come from data science.
Data science possesses various interdisciplinary areas such as statistics, scientific
methods, machine learning, artificial intelligence. It organizes the data for further analysis, and
to optimize the output of the investigation, it cleanses, aggregates and manipulates the data.
The analysis output brings us the hidden patterns hence deep informed insights for predictions
(n.d.).
Therefore, one can notice that we have a great tool to analyze the world around us.
However, this world is getting bigger and bigger every day radically, unorganized, and
continuously. The main aim here is to introduce research areas that try to find answers to the
challenging problems in data science.
1. Ethical concerns in data science researches:
Floridi and Taddeo (2016) illustrate data ethics as the branch of ethics, which explores
and evaluates moral problems about data, algorithms and related practices. We can concern
sharing, usage, processing, data generation, machine learning applications, and hacking and
advanced codes as specific research fields in the data ethics branch. Data ethics attempt to
analyze and judge the solutions of these fields (Floridi & Taddeo, 2016).
One of the responsibilities of data scientists is to maintain private data security (Lou &
Yang, 2020). From the companies side, transparency is critical to gaining the consumers’ trust.
We recently witnessed the Facebook Cambridge Analytica Data Scandal (Criddle, 2020).
Within morality focused company policies, we can bear the above problems. However, in the
case of preventing the algorithm from biases, we need to develop a new structure that
profoundly understands social life (Lou & Yang, 2020).
We are observing the biases, especially about gender equality cases. The following
examples, Figure 1. and Figure 2. can be shown as highlight situations that need to be
concerned instantly (Pisani, 2021).
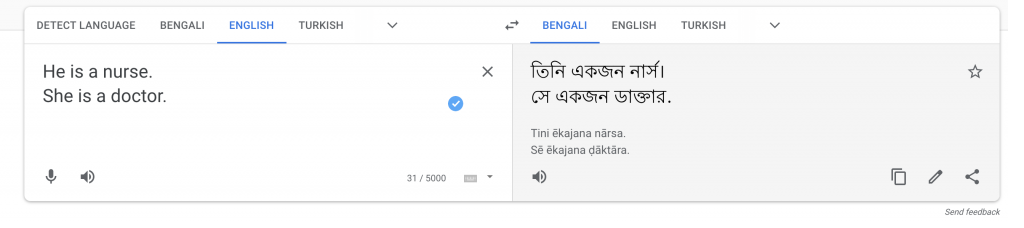
Figure 1. English to gender-neutral language Bengali translation
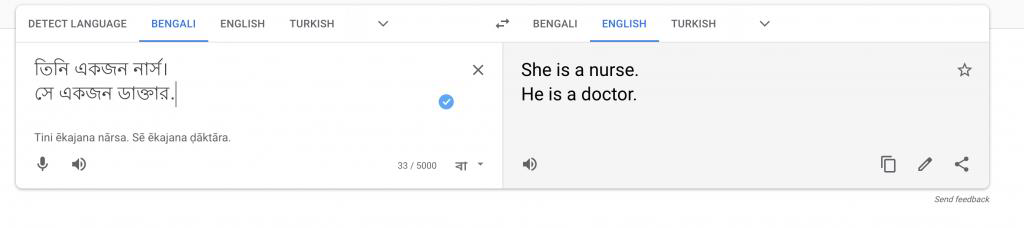
Figure 2. Gender-neutral language to English translation
One can notice that from Figure 1. the input is provided as “He is a nurse” and “She is a doctor.” Nevertheless, as shown in Figure 2. the genders are reversed such that “She is a nurse” and “He is a doctor.”. Mainly Bengali is selected because it is a gender-neutral language. Pisani (2021) stated that this situation occurs because historical data set the most probable output.
Hence, we can feed the algorithm with more proper and modern train models. Also, we should be careful about the human biased such as scientists’, programmers’ thoughts about the issue. We can work with a diverse team that tests the algorithm appropriately and estimates the results. Because not only gender, we have biases about ethnicity, religion and countries, which can effortlessly produce disasters in relations and influence the next generation’s mind (Pisani, 2021).
2. Data science algorithms to understand the deep learning mechanism:
It is remarked that deep learning is a type of artificial intelligence and machine learning model that proposes new ways to manage a big data problem (Das et al., 2020). Big data is a data set that cannot be analyzed by a traditional relational database management system
(RDBMS) (n.d.). Big data consists of high variety, high volume and high velocity (n.d.). Deep learning allows systems to analyze and process non-linear, complex and massive data sets by converting data into the cascade of layers (Das et al., 2020).
Wolfe (2021) remarked that the human brain decision-making mechanism inspires it. Neural networks in human brain analogy are simulated to deep learning algorithms such that communication is regulated between the layers. We can notice the analogy in Figure 3 between neurons in the human brain and the neural network system (Plehiers et al., 2019).
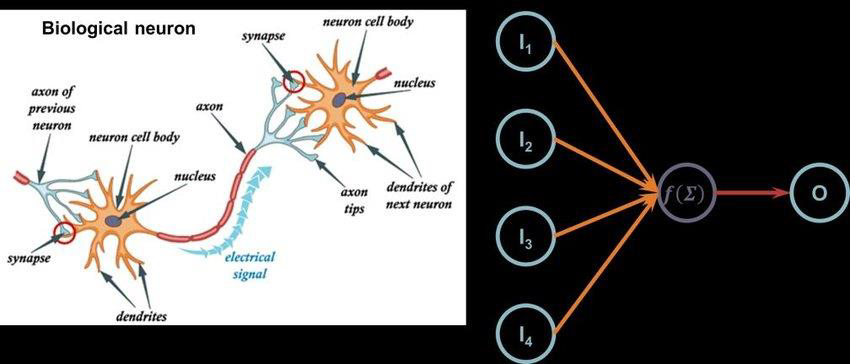
Figure 3. The analogy between neurons and neural networks.
To assemble the model more accurate and robust, we train the system with a large amount of data. The primary trick of deep learning is that concerned large amount of data should not be well-organized, structured or labeled. It can process a data set that is unstructured and unlabeled. Consequently, the process should be accomplished with more complex statistical models (Wolfe, 2021).
Deep learning is dealing with significant data challenges with alternative models. To negotiate with fast-moving and continuous input data, incremental learning for non-stationary data models is used. As described by Najafabadi et al. (2015), these models can be illustrated as incremental feature learning and extraction, denoising autoencoders and deep belief networks. Also, high dimensional data types with heavy volume raw data we solved by using marginalized stacked denoising autoencoders (MSDA) and convolutional neural networks (Najafabadi et al., 2015).
3. How to handle incomplete and noise data:
It is expressed that real-world data possesses meaningless data, which we call “noise” (Gupta & Gupta, 2019). The main aim is to make sense and find relative patterns from the data
set. However, noise behaves as a divergent factor for the algorithm (Goel, 2018). Hence, finding new algorithms to catch noise data and heal the data analysis process is crucial. The current methods can be sorted as collecting more data, component analysis, regularization in order to predict and heal the noise (Goel, 2018). One can observe the noisy data example in Figure 5 (Kashani et al., 2010).
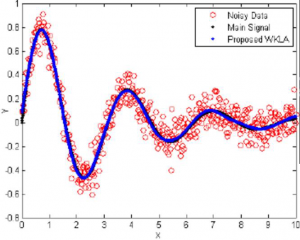 Figure 4. Noisy Data Example
Figure 4. Noisy Data Example
It is depicted by Gantayat et al. (2014), incomplete data can be defined as variables that
do not have observations or questions which do not have answers. We understand that small
distributions in the data set can cause serious divergent solutions and results. As Roy (2021) is
concerned, data science should be enhanced with machine learning algorithms and packages
that automatically detect and propagate incomplete data. One can see an example of incomplete
data in Figure 5 due to the utilization of data limits (Roy, 2021).
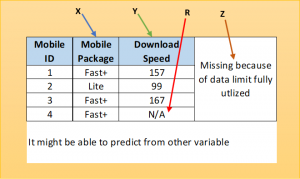
Figure 5. Incomplete Data Example
4. Alternative methods for data-intensive applications:
As Wing (2019) presents, computational speed and power are the primary considerations in traditional computational systems; however, the main focus is transferred to the data. Therefore, we need new heterogeneous computing processors and a proper setting for extensive data entry and applications, which helps our data analysis with energy efficiency. We can observe in Figure 6. below the relation between data complexity and computational complexity by considering the parameters of formats and models (Buyya et al., 2013).
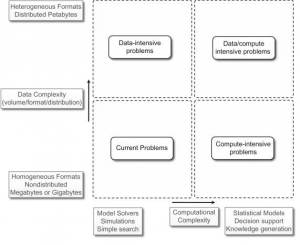
Figure 6. The relation between data complexity and computational complexity
We can conclude that we need heterogeneous formats and statistical models that support the decision with knowledge generation for the higher optimal solution for data analysis.
5. The Importance of Precious Data:
Sir Tim Berners stated that “Data is a precious thing and will last longer than the
systems themselves.” (Herbert & Budd, 2019). Wing (2019) discusses the precious data
properties in three conditions. According to Wing (2019), the data should be expensive to
collect, contain rare events, or represent specific research. The foremost challenge is separating
and new algorithms to analyze these three cases.
We can regard costly and massive scientific experience as expensive precious data.
Also, since these inputs consist of low signal to noise data, we can accept it as rare events data
set, too. One of the famous examples nowadays is exoplanet researches. Kepler and TESS
continuously collect the data from electromagnetic waves to determine astrobiological and
explanatory information. As an example, we can reach confirmed exoplanets from NASA
Exoplanet Archive (Barclay , 2021). In Figure 7. we can observe data analysis about masses
and radii of confirmed exoplanets (Herrera-Martín et al., 2020).
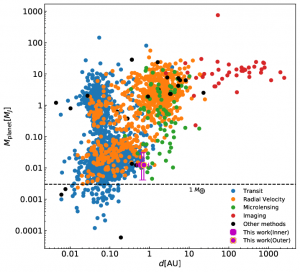
Figure 7. Data Analysis Example for Exoplanets
Consequently, the central aim of this research is to provide a brief introduction to some
challenging areas. Even if data science plays the role of a hero in most modern-day living, from
the healthcare system to financial accounting, there are still many problems to solve. The
primary motivation is to use the tremendous treasure in our hands and get meaning from it to
shape the concerned issue more healthily and logically.
REFERENCES
Barclay , T. (Ed.). (2021, December 6). Mission objectives. TESS. Retrieved December 30,
2021, from https://heasarc.gsfc.nasa.gov/docs/tess/objectives.html
Big Data Analytics. IBM. (n.d.). Retrieved December 9, 2021, from
https://www.ibm.com/analytics/hadoop/big-data-analytics
Buyya, R., Vecchiola, C., & Thamarai Selvi, S. (2013). Data-Intensive Computing.
Mastering Cloud Computing, 253–311. https://doi.org/10.1016/b978-0-12-411454-8.00008-5
Criddle, C. (2020, October 28). Facebook sued over Cambridge Analytica Data scandal.
BBC News. Retrieved December 9, 2021, from https://www.bbc.com/news/technology54722362
Das, H., Pradhan, C., & Dey, N. (2020). Deep Learning for Data Analytics: Foundations,
Biomedical Applications, and Challenges. Academic Press, an imprint of Elsevier.
Du, G., & Yu , M. (2018, June 8). You Can View Almost All the Chinese Court Judgments
Online for Free. China Justice Observer. Retrieved December 10, 2021, from
https://www.chinajusticeobserver.com/a/you-can-view-almost-all-the-chinese-courtjudgments-online-for-free
Floridi, L., & Taddeo, M. (2016). What is data ethics? Philosophical Transactions of the
Royal Society A: Mathematical, Physical and Engineering Sciences, 374(2083), 1–5.
https://doi.org/10.1098/rsta.2016.0360
Gantayat, S. S., Misra, A., & Panda, B. S. (2014). A study of Incomplete Data – A Review.
Proceedings of the International Conference on Frontiers of Intelligent Computing:
Theory and Applications (FICTA) 2013, 401–408. https://doi.org/10.1007/978-3-319-02931-3_45
Goel, A. (2018, April 27). How to Manage Noisy Data. Magoosh Data Science Blog.
Retrieved December 9, 2021, from https://magoosh.com/data-science/what-is-deeplearning-ai/
Gupta, S., & Gupta, A. (2019). Dealing with Noise Problem in Machine Learning Data-sets:
A Systematic Review. Procedia Computer Science, 161, 466–474.
https://doi.org/10.1016/j.procs.2019.11.146
Herbert, T., & Budd, A. (2019, March 13). Sir Tim Berners-Lee: Net worth, best quotes and
incredible achievements of the World Wide Web inventor. Evening Standard. Retrieved
December 9, 2021, from https://www.standard.co.uk/tech/who-is-tim-berners-leeworld-wide-web-www-inventor-net-worth-facts-quotes-a4088781.html
Herrera-Martín, A., Albrow, M. D., Udalski, A., Gould, A., Ryu, Y.-H., Yee, J. C., Chung,
S.-J., Han, C., Hwang, K.-H., Jung, Y. K., Lee, C.-U., Shin, I.-G., Shvartzvald, Y.,
Zang, W., Cha, S.-M., Kim, D.-J., Kim, H.-W., Kim, S.-L., Lee, D.-J., … Wrona, M.
(2020). Ogle-2018-BLG-0677Lb: A super-earth near the Galactic bulge. The
Astronomical Journal, 159(6), 256. https://doi.org/10.3847/1538-3881/ab893e
Kashani, H. B., Seyedin, S. A., & Yazdi, H. S. (2010). A Novel Approach in Video Scene
Background Estimation. International Journal of Computer Theory and Engineering,
274–282. https://doi.org/10.7763/ijcte.2010.v2.152
Lou, S., & Yang, M. (2020, August 12). A Beginner’s Guide to Data Ethics. Medium.
Retrieved December 9, 2021, from https://medium.com/big-data-at-berkeley/thingsyou-need-to-know-before-you-become-a-data-scientist-a-beginners-guide-to-dataethics-8f9aa21af742
Najafabadi, M. M., Villanustre, F., Khoshgoftaar, T. M., Seliya, N., Wald, R., &
Muharemagic, E. (2015). Deep Learning Applications and Challenges in Big Data
Analytics. Journal of Big Data, 2(1), 1–21. https://doi.org/10.1186/s40537-014-0007-7
Pisani, M. (2021, June 14). How Women Need to Be Involved in Data Science to Prevent Bias
in Algorithms. Rootstrap. Retrieved December 9, 2021, from
https://www.rootstrap.com/blog/how-women-need-to-be-involved-in-data-science-toprevent-bias-in-algorithms/
Plehiers, P. P., Symoens, S. H., Amghizar, I., Marin, G. B., Stevens, C. V., & Van Geem, K.
M. (2019). Artificial Intelligence in steam cracking modeling: A deep learning
algorithm for detailed effluent prediction. Engineering, 5(6), 1027–1040.
https://doi.org/10.1016/j.eng.2019.02.013
Rapose, R. (2021, March 15). How dataism is revolutionizing the idea of the individual (no
fluff). Medium. Retrieved December 9, 2021, from
https://towardsdatascience.com/how-dataism-is-revolutionizing-the-idea-of-theindividual-no-fluff-74bda98ff5f8?source=post_internal_links———0———————
Roy, B. (2021, June 27). All About Missing Data Handling. Medium. Retrieved December 9,
2021, from https://towardsdatascience.com/all-about-missing-data-handlingb94b8b5d2184
What is Data Science? Oracle. (n.d.). Retrieved December 9, 2021, from
https://www.oracle.com/data-science/what-is-data-science/
Wing, J. M. (2019, December 30). Ten Research Challenge Areas in Data Science. The Data
Science Institute at Columbia University. Retrieved December 9, 2021, from
https://datascience.columbia.edu/news/2019/ten-research-challenge-areas-in-datascience/
Wolfe, M. (2021, September 15). Deep Learning in data science. Medium. Retrieved
December 9, 2021, from https://towardsdatascience.com/deep-learning-in-data-sciencef34b4b124580